









Home
Perspectives
The data conductor
The data conductor
In order to develop artificial intelligence (AI) for use in medical technology, our research scientists need one thing above all: colossal quantities of all kinds of correct and secure medical data. Ren-Yi Lo, Head of our Big Data Office, is in charge of collecting, preparing, and organizing these data. So, what does all that have to do with music? Learn that and more in part six of our #Futureshaper series.
A "data lake" is, in principle, exactly what the term suggests: a giant "lake" of semi-structured data. Based in Princeton, New Jersey, USA colleague Ren-Yi Lo manages one such data lake together with her international team.
What is big data?

What is artificial intelligence (AI)?
The quality of the data is decisive
What does data curation mean?
Big data: Invisible, yet essential
Become part of the Siemens Healthineers team
Are you also interested in joining our enthusiastic team?
I sometimes feel a bit like I'm a 'Jill of all trades*. But I suppose that's really exactly what I have to be for my job.
Ren-Yi Lo
Head of Big Data Office, Siemens Healthineers

- Data are used by researchers in the field of AI to train algorithms that are of fundamental importance to our future technologies. When AI scientists invent something for improving the training methods used or the algorithms themselves, then such inventions can also be protected by patents. At Siemens Healthineers, a team of patent attorneys from Intellectual Property Department work closely with our AI scientists to identify valuable discoveries and inventions and strategically protect them against plagiarists. Siemens Healthineers holds some 23,000 intellectual property rights, of which over 15,000 are granted patents.
How can AI optimize laboratory workflows?
How do you generate a computer model of the human liver?
Senior AI research scientist Chloé Audigier is conducting research aimed at creating a digital twin of the human liver. Such models can help physicians simulate multiple treatment options.
- <p><strong>Data from medical imaging</strong> include, for example, radiographic (X-ray) images, computed tomography (CT) scans, magnetic resonance imaging (MRI), and ultrasonic images. Accompanying <strong>medical reports</strong> contain background information on the medical history of patients and the treatments administered. Data from <strong>laboratory diagnostics</strong> comprise, for example, results from laboratory testing of blood, urine, and body tissue. <strong>Genomic data</strong> are data derived from DNA analyses. <strong>Operational data</strong> contain information on operational workflows in physicians' practices or hospitals, as well as on maintenance work performed on medical devices, etc.</p>
The right data cohorts
What is a cohort?
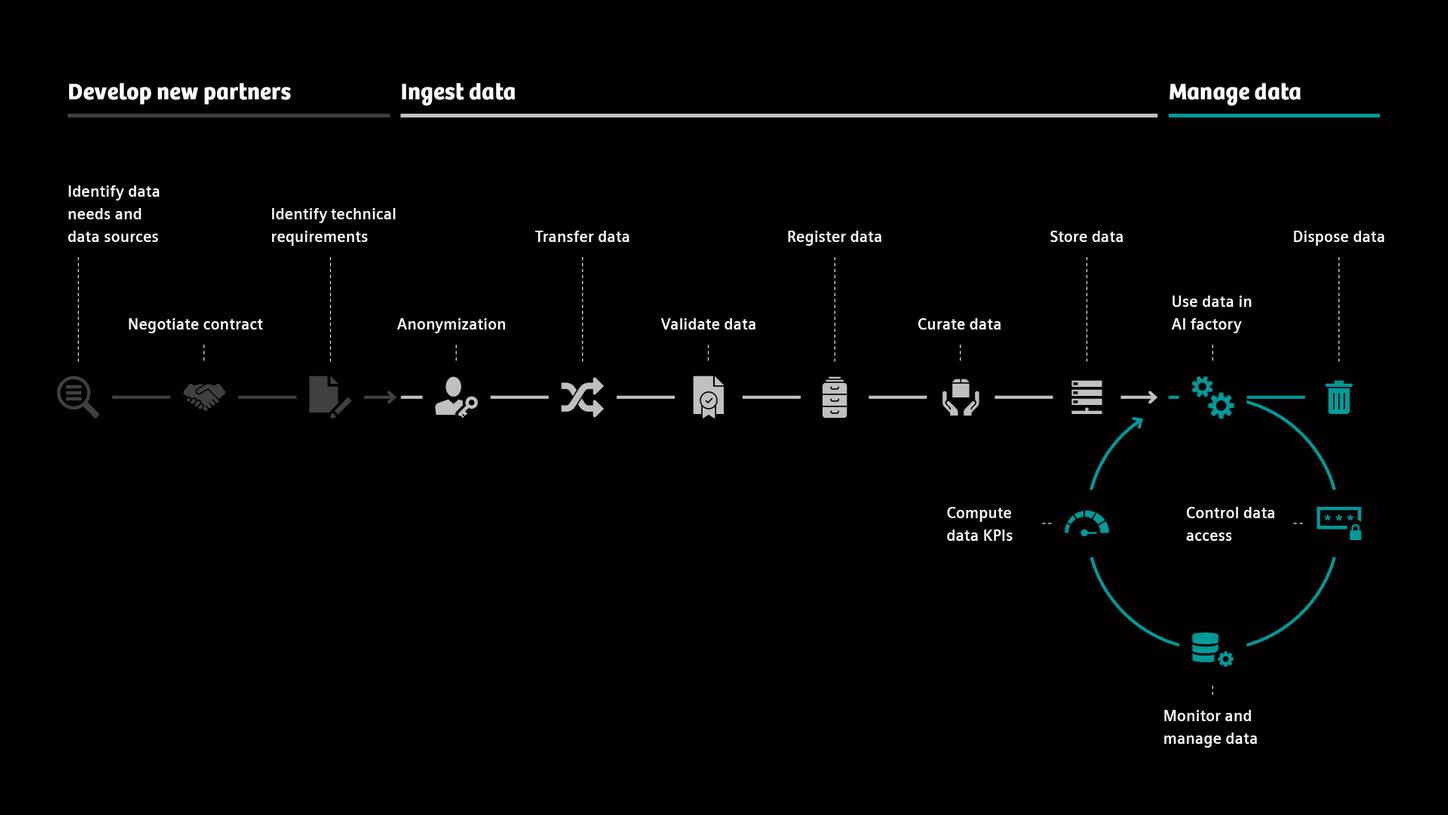
Complex standardized process
Process overview of the data lifecycle
What is the GDPR?
Anonymization is essential
What is the FDA?
Sherlock, the AI supercomputer
What is a terabyte?
Want to read more about the AI RAD Companion?
The big opportunities of digital models
Share this page
Katja Gäbelein works as an editor in corporate communications at Siemens Healthineers, and specializes in technology and innovation topics. She writes for text and film media.
Assistant editor: Guadalupe Sanchez
- Sources
Al-Mekhlal, Monerah; Khwaja, Amir Ali (2019): A Synthesis of Big Data Definition and Characteristics. In: IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC). pp. 314-322. Available online: https://ieeexplore.ieee.org/abstract/document/8919591
Gethmann, Carl Friedrich; Buxmann, Peter; Distelrah, Julia; Humm, Bernhard G.; Lingner, Stephan; Nitsch, Verena; Schmidt, Jan C.; Spiecker (Döhmann), Indra (2022): Künstliche Intelligenz in der Forschung – Neue Möglichkeiten und Herausforderungen für die Wissenschaft. (Artificial intelligence in research – New opportunities and challenges for science) Berlin: Springer, p. 8.
- Disclaimer
- The presented information is based on research results that are not commercially available. Its future availability cannot be ensured.
- The figures shown here are as of February 2023.